※美國陸軍研製出能加快士兵培訓的人工智能系統※
2018年04月30日14:28
南加州大學和美軍實驗室的科學家們研製出新型人工智能系統,能夠幫助士兵訓練注意力、記憶力和在戰場上表現更理性,將士兵培訓速度顯著加快。
阿德爾菲市美國陸軍研究實驗室的拉季戈帕爾·坎楠表示,“這一系統將成為新一代步兵戰車的一部分,成為其程序填充的組成部分之一,能夠幫助士兵收集、整合和處理戰場各角落戰鬥進展的信息。”
近年來由於數學的發展和計算機計算能力的提高,使科學家能夠創建複雜的神經網絡和能夠執行特殊任務的人工智能系統,同時創造出藝術和工藝的新模式。
例如,僅在近兩年,科學家就研製出大量人工智能系統,能夠打敗中國古代遊戲人物,尋找報紙中歷史上最重要的事件,為電腦遊戲編寫劇本,為梵高的圖片和視頻塗色,創作自己的繪畫作品。2017年初,科學家們推出了比最有經驗的皮膚科醫生能更好區別皮膚癌和斑痣的人工智能系統。
美國陸軍和南加州大學的數學家長期以來一直在試圖建立能夠幫助士兵快速找到例如地雷等潛在危險源的人工智能系統,更準確地評估戰場上潛在庇護所的利害。
※人工智慧的歷史※
人工智慧的歷史源遠流長。在古代的神話傳說中,技藝高超的工匠可以製作人造人,並為其賦予智能或意識。現代意義上的AI始於古典哲學家用機械符號處理的觀點解釋人類思考過程的嘗試。20世紀40年代基於抽象數學推理的可程式數字計算機的發明使一批科學家開始嚴肅地探討構造一個電子大腦的可能性。
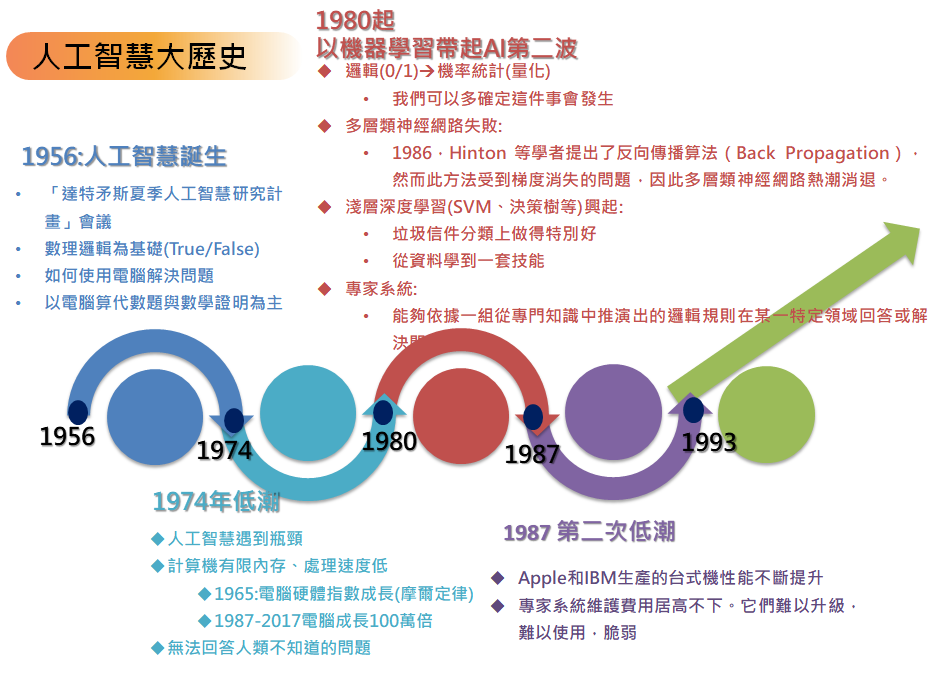
1956年,在達特茅斯學院舉行的一次會議上正式確立了人工智慧的研究領域。會議的參加者在接下來的數十年間是AI研究的領軍人物。他們中有許多人預言,經過一代人的努力,與人類具有同等智能水平的機器將會出現。同時,上千萬美元被投入到AI研究中,以期實現這一目標。
研究人員發現自己大大低估了這一工程的難度,人工智慧史上共出現過好幾次低潮。由於詹姆斯·萊特希爾爵士的批評和國會方面的壓力,美國和英國政府於1973年停止向沒有明確目標的人工智慧研究項目撥款。七年之後受到日本政府研究規劃的刺激,美國政府和企業再次在AI領域投入數十億研究經費,但這些投資者在80年代末重新撤回了投資。AI研究領域諸如此類的高潮和低谷不斷交替出現;至今仍有人對AI的前景作出異常樂觀的預測。
儘管在政府官僚和風投資本家那裡經歷了大起大落,AI領域仍在取得進展。某些在20世紀70年代被認為不可能解決的問題今天已經獲得了圓滿解決並已成功應用在商業產品上。與第一代AI研究人員的樂觀估計不同,具有與人類同等智能水平的機器至今仍未出現。圖靈在1950年發表的一篇催生現代智能機器研究的著名論文中稱,「我們只能看到眼前的一小段距離……但是,我們可以看到仍有許多工作要做」。
先驅
McCorduck寫道:「某種形式上的人工智慧是一個遍布於西方知識分子歷史的觀點,是一個急需被實現的夢想,」先民對人工智慧的追求表現在諸多神話,傳說,故事,預言以及製作機器人偶(自動機)的實踐之中。
神話,幻想和預言中的AI
希臘神話中已經出現了機械人和人造人,如赫淮斯托斯的黃金機器人和皮格馬利翁的伽拉忒亞。中世紀出現了使用巫術或鍊金術將意識賦予無生命物質的傳說,如賈比爾的Takwin,帕拉塞爾蘇斯的何蒙庫魯茲和Judah Loew的魔像。19世紀的幻想小說中出現了人造人和會思考的機器之類題材,例如瑪麗·雪萊的《弗蘭肯斯坦》和卡雷爾·恰佩克的《羅素姆的萬能機器人》。Samuel Butler的《機器中的達爾文(Darwin among the Machines)》一文(1863)探討了機器通過自然選擇進化出智能的可能性。至今人工智慧仍然是科幻小說的重要元素。
自動人偶 -自動機
加扎利的可程式自動人偶(1206年) 許多文明中都有創造自動人偶的傑出工匠,例如偃師(中國西周),希羅(希臘),加扎利和Wolfgang von Kempelen等等。已知最古老的「機器人」是古埃及和古希臘的聖像,忠實的信徒認為工匠為這些神像賦予了思想,使它們具有智慧和激情。赫耳墨斯·特里斯墨吉斯忒斯(赫耳墨斯·特里斯墨吉斯忒斯)寫道「當發現神的本性時,人就能夠重現他」

形式推理
人工智慧的基本假設是人類的思考過程可以機械化。對於機械化推理(即所謂「形式推理(formal reasoning)」)的研究已有很長歷史。中國,印度和希臘哲學家均已在公元前的第一個千年裡提出了形式推理的結構化方法。他們的想法為後世的哲學家所繼承和發展,其中著名的有亞里士多德(對三段論邏輯進行了形式分析),歐幾里得(其著作《幾何原本》是形式推理的典範),花剌子密(代數學的先驅,「algorithm」一詞由他的名字演變而來)以及一些歐洲經院哲學家,如奧卡姆的威廉和鄧斯·司各脫。
馬略卡哲學家拉蒙·柳利(1232-1315)開發了一些「邏輯機」,試圖通過邏輯方法獲取知識。柳利的機器能夠將基本的,無可否認的真理通過機械手段用簡單的邏輯操作進行組合,以求生成所有可能的知識。Llull的工作對萊布尼茲產生了很大影響,後者進一步發展了他的思想。
萊布尼茲猜測人類的思想可以簡化為機械計算 在17世紀中,萊布尼茲,托馬斯·霍布斯和笛卡兒嘗試將理性的思考系統化為代數學或幾何學那樣的體系。霍布斯在其著作《利維坦》中有一句名言:「推理就是計算(reason is nothing but reckoning)。」 萊布尼茲設想了一種用於推理的普適語言(他的通用表意文字),能將推理規約為計算,從而使「哲學家之間,就像會計師之間一樣,不再需要爭辯。他們只需拿出鉛筆放在石板上,然後向對方說(如果想要的話,可以請一位朋友作為證人):『我們開始算吧。』」這些哲學家已經開始明確提出形式符號系統的假設,而這一假設將成為AI研究的指導思想。
在20世紀,數理邏輯研究上的突破使得人工智慧好像呼之欲出。這方面的基礎著作包括布爾的《思維的定律》與弗雷格的《概念文字》。基於弗雷格的系統,羅素和懷特海在他們於1913年出版的巨著《數學原理》中對數學的基礎給出了形式化描述。這一成就激勵了希爾伯特,後者向20世紀20年代和30年代的數學家提出了一個基礎性的難題:「能否將所有的數學推理形式化?」這個問題的最終回答由哥德爾不完備定理,圖靈機和Alonzo Church的λ演算給出。他們的答案令人震驚:首先,他們證明了數理邏輯的局限性;其次(這一點對AI更重要),他們的工作隱含了任何形式的數學推理都能在這些限制之下機械化的可能性。
邱奇-圖靈論題暗示,一台僅能處理0和1這樣簡單二元符號的機械設備能夠模擬任意數學推理過程。這裡最關鍵的靈感是圖靈機:這一看似簡單的理論構造抓住了抽象符號處理的本質。這一創造激發科學家們探討讓機器思考的可能。
計算機科學 -計算機硬體歷史
用於計算的機器古已有之;歷史上許多數學家對其作出了改進。19世紀初,查爾斯·巴貝奇設計了一台可程式計算機(「分析機」),但未能建造出來。愛達·勒芙蕾絲預言,這台機器「將創作出無限複雜,無限寬廣的精妙的科學樂章」。(她常被認為是第一個程式設計師,因為她留下的一些筆記完整地描述了使用這一機器計算伯努利數的方法。)
第一批現代計算機是二戰期間建造的大型解碼機(包括Z3,ENIAC和Colossus等)。後兩個機器的理論基礎是圖靈和約翰·馮·諾伊曼提出和發展的學說。
人工智慧的誕生:1943 - 1956
在20世紀40年代和50年代,來自不同領域(數學,心理學,工程學,經濟學和政治學)的一批科學家開始探討製造人工大腦的可能性。1956年,人工智慧被確立為一門學科。
控制論與早期神經網絡
最初的人工智慧研究是30年代末到50年代初的一系列科學進展交匯的產物。神經學研究發現大腦是由神經元組成的電子網絡,其激勵電平只存在「有」和「無」兩種狀態,不存在中間狀態。維納的控制論描述了電子網絡的控制和穩定性。克勞德·香農提出的資訊理論則描述了數位訊號(即高低電平代表的二進位信號)。圖靈的計算理論證明數位訊號足以描述任何形式的計算。這些密切相關的想法暗示了構建電子大腦的可能性。
這一階段的工作包括一些機器人的研發,例如W. Grey Walter的「烏龜(turtles)」,還有「約翰霍普金斯獸」(Johns Hopkins Beast)。這些機器並未使用計算機,數字電路和符號推理;控制它們的是純粹的模擬電路。
Walter Pitts和Warren McCulloch分析了理想化的人工神經元網絡,並且指出了它們進行簡單邏輯運算的機制。他們是最早描述所謂「神經網絡」的學者。馬文·明斯基是他們的學生,當時是一名24歲的研究生。1951年他與Dean Edmonds一道建造了第一台神經網絡機,稱為SNARC。在接下來的五十年中,明斯基是AI領域最重要的領導者和創新者之一。
遊戲AI
1951年,Christopher Strachey使用曼徹斯特大學的Ferranti Mark 1機器寫出了一個西洋跳棋(checkers)程序;Dietrich Prinz則寫出了一個西洋棋程序。亞瑟·山謬爾(Arthur Samuel)在五十年代中期和六十年代初開發的西洋棋程序的棋力已經可以挑戰具有相當水平的業餘愛好者。遊戲AI一直被認為是評價AI進展的一種標準。
圖靈測試
1950年,圖靈發表了一篇劃時代的論文,文中預言了創造出具有真正智能的機器的可能性。由於注意到「智能」這一概念難以確切定義,他提出了著名的圖靈測試:如果一台機器能夠與人類展開對話(通過電傳設備)而不能被辨別出其機器身份,那麼稱這台機器具有智能。這一簡化使得圖靈能夠令人信服地說明「思考的機器」是可能的。論文中還回答了對這一假說的各種常見質疑。圖靈測試是人工智慧哲學方面第一個嚴肅的提案。
符號推理與「邏輯理論家」程序
50年代中期,隨著數字計算機的興起,一些科學家直覺地感到可以進行數字操作的機器也應當可以進行符號操作,而符號操作可能是人類思維的本質。這是創造智能機器的一條新路。
1955年,艾倫·紐厄爾和後來榮獲諾貝爾獎的赫伯特·西蒙在J. C. Shaw的協助下開發了「邏輯理論家(Logic Theorist)」。這個程序能夠證明《數學原理》中前52個定理中的38個,其中某些證明比原著更加新穎和精巧。Simon認為他們已經「解決了神秘的心/身問題,解釋了物質構成的系統如何獲得心靈的性質。」
(這一斷言的哲學立場後來被John Searle稱為「強人工智慧」,即機器可以像人一樣具有思想。)

1956年達特茅斯會議:AI的誕生
1956年達特矛斯會議的組織者是馬文·明斯基,約翰·麥卡錫和另兩位資深科學家克勞德·香農以及內森·羅徹斯特(Nathan Rochester),後者來自IBM。會議提出的斷言之一是「學習或者智能的任何其他特性的每一個方面都應能被精確地加以描述,使得機器可以對其進行模擬。」與會者包括雷·索羅門諾夫(Ray Solomonoff),奧利佛·塞爾弗里奇(Oliver Selfridge),Trenchard More,亞瑟·山謬爾(Arthur Samuel),艾倫·紐厄爾和赫伯特·西蒙,他們中的每一位都將在AI研究的第一個十年中作出重要貢獻。會上紐厄爾和西蒙討論了「邏輯理論家」,而麥卡錫則說服與會者接受「人工智慧」一詞作為本領域的名稱。1956年達特矛斯會議上AI的名稱和任務得以確定,同時出現了最初的成就和最早的一批研究者,因此這一事件被廣泛承認為AI誕生的標誌。
黃金年代:1956 - 1974
達特茅斯會議之後的數年是大發現的時代。對許多人而言,這一階段開發出的程序堪稱神奇:計算機可以解決代數應用題,證明幾何定理,學習和使用英語。當時大多數人幾乎無法相信機器能夠如此「智能」。研究者們在私下的交流和公開發表的論文中表達出相當樂觀的情緒,認為具有完全智能的機器將在二十年內出現。DARPA(國防高等研究計劃署)等政府機構向這一新興領域投入了大筆資金。
研究工作
從50年代後期到60年代湧現了大批成功的AI程序和新的研究方向。下面列舉其中最具影響的幾個。
搜索式推理
許多AI程序使用相同的基本算法。為實現一個目標(例如贏得遊戲或證明定理),它們一步步地前進,就像在迷宮中尋找出路一般;如果遇到了死胡同則進行回溯。這就是「搜索式推理」。
這一思想遇到的主要困難是,在很多問題中,「迷宮」里可能的線路總數是一個天文數字(所謂「指數爆炸」)。研究者使用啟發式算法去掉那些不太可能導出正確答案的支路,從而縮小搜索範圍。
艾倫·紐厄爾和赫伯特·西蒙試圖通過其「通用解題器(General Problem Solver)」程序,將這一算法推廣到一般情形。另一些基於搜索算法證明幾何與代數問題的程序也給人們留下了深刻印象,例如赫伯特·吉寧特(Herbert Gelernter)的幾何定理證明機(1958)和馬文·李·閔斯基的學生James Slagle開發的SAINT(1961)。[52]還有一些程序通過搜索目標和子目標作出決策,如史丹福大學為控制機器人Shakey而開發的STRIPS系統。
自然語言
AI研究的一個重要目標是使計算機能夠通過自然語言(例如英語)進行交流。早期的一個成功範例是Daniel Bobrow的程序STUDENT,它能夠解決高中程度的代數應用題。
如果用節點表示語義概念(例如「房子」,「門」),用節點間的連線表示語義關係(例如「有 -- 一個」),就可以構造出「語義網(semantic net)」。第一個使用語義網的AI程序由Ross Quillian開發;而最為成功(也是最有爭議)的一個則是Roger Schank的「概念關聯(Conceptual Dependency)」。
Joseph Weizenbaum的ELIZA是第一個聊天機器人,可能也是最有趣的會說英語的程序。與ELIZA「聊天」的用戶有時會誤以為自己是在和人類,而不是和一個程序,交談。但是實際上ELIZA根本不知道自己在說什麼。它只是按固定套路作答,或者用符合語法的方式將問題複述一遍。
微世界
60年代後期,麻省理工大學AI實驗室的馬文·閔斯基和西摩爾·派普特建議AI研究者們專注於被稱為「微世界」的簡單場景。他們指出在成熟的學科中往往使用簡化模型幫助基本原則的理解,例如物理學中的光滑平面和完美剛體。許多這類研究的場景是「積木世界」,其中包括一個平面,上面擺放著一些不同形狀,尺寸和顏色的積木。
在這一指導思想下,傑拉德·傑伊·薩斯曼(研究組長),Adolfo Guzman,大衛·瓦爾茲(David Waltz,「約束傳播(constraint propagation)」的提出者),特別是Patrick Winston等人在機器視覺領域作出了創造性貢獻。同時,Minsky和Papert製作了一個會搭積木的機器臂,從而將「積木世界」變為現實。微世界程序的最高成就是Terry Winograd的SHRDLU,它能用普通的英語句子與人交流,還能作出決策並執行操作。
樂觀思潮
第一代AI研究者們曾作出了如下預言:
(1)1958年,艾倫·紐厄爾和赫伯特·西蒙:「十年之內,數字計算機將成為西洋棋世界冠軍。」 「十年之內,數字計算機將發現並證明一個重要的數學定理。」
(2)1965年,赫伯特·西蒙:「二十年內,機器將能完成人能做到的一切工作。」
(3)1967年,馬文·閔斯基:「一代之內……創造『人工智慧』的問題將獲得實質上的解決。」
(4)1970年,馬文·閔斯基:「在三到八年的時間裡我們將得到一台具有人類平均智能的機器。」
經費
1963年6月,MIT從新建立的ARPA(即後來的DARPA,國防高等研究計劃局)獲得了二百二十萬美元經費,用於資助MAC工程,其中包括Minsky和McCarthy五年前建立的AI研究組。此後ARPA每年提供三百萬美元,直到七十年代為止。ARPA還對艾倫·紐厄爾和赫伯特·西蒙在卡內基梅隆大學的工作組以及史丹福大學AI項目(由John McCarthy於1963年創建)進行類似的資助。另一個重要的AI實驗室於1965年由Donald Michie在愛丁堡大學建立。在接下來的許多年間,這四個研究機構一直是AI學術界的研究(和經費)中心。
經費幾乎是無條件地提供的:時任ARPA主任的J. C. R. Licklider相信他的組織應該「資助人,而不是項目」,並且允許研究者去做任何感興趣的方向。這導致了MIT無約無束的研究氛圍及其hacker文化的形成,但是好景不長。
第一次AI低谷:1974 - 1980
到了70年代,AI開始遭遇批評,隨之而來的還有資金上的困難。AI研究者們對其課題的難度未能作出正確判斷:此前的過於樂觀使人們期望過高,當承諾無法兌現時,對AI的資助就縮減或取消了。同時,由於馬文·閔斯基對感知器的激烈批評,聯結主義(即神經網絡)銷聲匿跡了十年。70年代後期,儘管遭遇了公眾的誤解,AI在邏輯編程,常識推理等一些領域還是有所進展。

問題
70年代初,AI遭遇了瓶頸。即使是最傑出的AI程序也只能解決它們嘗試解決的問題中最簡單的一部分,也就是說所有的AI程序都只是「玩具」。AI研究者們遭遇了無法克服的基礎性障礙。儘管某些局限後來被成功突破,但許多至今仍無法滿意地解決。
1.計算機的運算能力。當時的計算機有限的內存和處理速度不足以解決任何實際的AI問題。例如,羅斯·奎利恩(Ross Quillian)在自然語言方面的研究結果只能用一個含二十個單詞的詞彙表進行演示,因為內存只能容納這麼多。1976年,漢斯·莫拉維克指出,計算機離智能的要求還差上百萬倍。他做了個類比:人工智慧需要強大的計算能力,就像飛機需要大功率動力一樣,低於一個門限時是無法實現的;但是隨著能力的提升,問題逐漸會變得簡單。
2.計算複雜性和指數爆炸。1972年理察·卡普根據史提芬·古克於1971年提出的Cook-Levin理論證明,許多問題只可能在指數時間內獲解(即,計算時間與輸入規模的冪成正比)。除了那些最簡單的情況,這些問題的解決需要近乎無限長的時間。這就意味著AI中的許多玩具程序恐怕永遠也不會發展為實用的系統。
3.常識與推理。許多重要的AI應用,例如機器視覺和自然語言,都需要大量對世界的認識信息。程序應該知道它在看什麼,或者在說些什麼。這要求程序對這個世界具有兒童水平的認識。研究者們很快發現這個要求太高了:1970年沒人能夠做出如此巨大的資料庫,也沒人知道一個程序怎樣才能學到如此豐富的信息。
4.莫拉維克悖論。證明定理和解決幾何問題對計算機而言相對容易,而一些看似簡單的任務,如人臉識別或穿過屋子,實現起來卻極端困難。這也是70年代中期機器視覺和機器人方面進展緩慢的原因。
5.框架和資格問題。採取邏輯觀點的AI研究者們(例如John McCarthy)發現,如果不對邏輯的結構進行調整,他們就無法對常見的涉及自動規劃(planning or default reasoning)的推理進行表達。為解決這一問題,他們發展了新邏輯學(如非單調邏輯(non-monotonic logics)和模態邏輯(modal logics))。
停止撥款
由於缺乏進展,對AI提供資助的機構(如英國政府,DARPA和NRC)對無方向的AI研究逐漸停止了資助。早在1966年ALPAC(Automatic Language Processing Advisory Committee,自動語言處理顧問委員會)的報告中就有批評機器翻譯進展的意味,預示了這一局面的來臨。NRC(National Research Council,美國國家科學委員會)在撥款二千萬美元後停止資助。1973年詹姆斯·萊特希爾針對英國AI研究狀況的報告批評了AI在實現其「宏偉目標」上的完全失敗,並導致了英國AI研究的低潮(該報告特別提到了指數爆炸問題,以此作為AI失敗的一個原因)。DARPA則對CMU的語音理解研究項目深感失望,從而取消了每年三百萬美元的資助。到了1974年已經很難再找到對AI項目的資助。
Hans Moravec將批評歸咎於他的同行們不切實際的預言:「許多研究者落進了一張日益浮誇的網中」。還有一點,自從1969年Mansfield修正案通過後,DARPA被迫只資助「具有明確任務方向的研究,而不是無方向的基礎研究」。60年代那種對自由探索的資助一去不復返;此後資金只提供給目標明確的特定項目,比如自動坦克,或者戰役管理系統。
來自大學的批評
一些哲學家強烈反對AI研究者的主張。其中最早的一個是John Lucas,他認為哥德爾不完備定理已經證明形式系統(例如電腦程式)不可能判斷某些陳述的真理性,但是人類可以。修伯特·德雷福斯(Hubert Dreyfus)諷刺六十年代AI界那些未實現的預言,並且批評AI的基礎假設,認為人類推理實際上僅涉及少量「符號處理」,而大多是具體的,直覺的,下意識的「竅門(know how)」。約翰·希爾勒於1980年提出「中文房間」實驗,試圖證明程序並不「理解」它所使用的符號,即所謂的「意向性(intentionality)」問題。希爾勒認為,如果符號對於機器而言沒有意義,那麼就不能認為機器是在「思考」。
AI研究者們並不太把這些批評當回事,因為它們似乎有些離題,而計算複雜性和「讓程序具有常識」等問題則顯得更加緊迫和嚴重。對於實際的電腦程式而言,「常識」和「意向性」的區別並不明顯。馬文·閔斯基提到德雷福斯和希爾勒時說,「他們誤解了,所以應該忽略」。在MIT任教的德雷福斯遭到了AI陣營的冷遇:他後來說,AI研究者們「生怕被人看到在和我一起吃中飯」。ELIZA程序的作者約瑟夫·維森鮑姆感到他的同事們對待德雷福斯的態度不太專業,而且有些孩子氣。雖然他直言不諱地反對德雷福斯的論點,但他「清楚地表明了他們待人的方式不對」。
約瑟夫·維森鮑姆後來開始思考AI相關的倫理問題,起因是Kenneth Colby開發了一個模仿醫師的聊天機器人DOCTOR,並用它當作真正的醫療工具。二人發生爭執;雖然Colby認為約瑟夫·維森鮑姆對他的程序沒有貢獻,但這於事無補。1976年約瑟夫·維森鮑姆出版著作《計算機的力量與人類的推理》,書中表示人工智慧的濫用可能損害人類生命的價值。
感知器與聯結主義遭到冷落
感知器是神經網絡的一種形式,由Frank Rosenblatt於1958年提出。與多數AI研究者一樣,他對這一發明的潛力非常樂觀,預言說「感知器最終將能夠學習,作出決策和翻譯語言」。整個六十年代裡這一方向的研究工作都很活躍。
1969年Minsky和Papert出版了著作《感知器》,書中暗示感知器具有嚴重局限,而Frank Rosenblatt的預言過於誇張。這本書的影響是破壞性的:聯結主義的研究因此停滯了十年。後來新一代研究者使這一領域獲得重生,並使其成為人工智慧中的重要部分;遺憾的是Rosenblatt沒能看到這些,他在《感知器》問世後不久即因遊船事故去世。
「簡約派(the neats)」:邏輯,Prolog語言和專家系統
早在1958年,John McCarthy就提出了名為「納諫者(Advice Taker)」的一個程序構想,將邏輯學引入了AI研究界。1963年,J. Alan Robinson發現了在計算機上實現推理的簡單方法:歸結(resolution)與合一(unification)算法。然而,根據60年代末McCarthy和他的學生們的工作,對這一想法的直接實現具有極高的計算複雜度:即使是證明很簡單的定理也需要天文數字的步驟。70年代Robert Kowalsky在Edinburgh大學的工作則更具成效:法國學者Alain Colmerauer和Phillipe Roussel在他的合作下開發出成功的邏輯程式語言Prolog。Prolog使用一組邏輯(與"規則"和"生產規則"密切相關的"霍恩子句"),並允許進行可處理的計算。規則持續帶來影響,為愛德華·費根鮑姆(Edward Feigenbaum)的專家系統以及艾倫·紐厄爾和赫伯特·西蒙的工作奠定基礎,使其完成了Soar及認知統一理論。
Dreyfus等人針對邏輯方法的批評觀點認為,人類在解決問題時並沒有使用邏輯運算。心理學家Peter Wason,Eleanor Rosch,阿摩司·特沃斯基,Daniel Kahneman等人的實驗證明了這一點。McCarthy則回應說,人類怎麼思考是無關緊要的:真正想要的是解題機器,而不是模仿人類進行思考的機器。
「蕪雜派(the scruffies)」:框架和腳本
對McCarthy的做法持批評意見的還有他在MIT的同行們。馬文·閔斯基,Seymour Papert和Roger Schank等試圖讓機器像人一樣思考,使之能夠解決「理解故事」和「目標識別」一類問題。為了使用「椅子」,「飯店」之類最基本的概念,他們需要讓機器像人一樣作出一些非邏輯的假設。不幸的是,這些不精確的概念難以用邏輯進行表達。Gerald Sussman注意到,「使用精確的語言描述本質上不精確的概念,並不能使它們變得精確起來」。Schank用「蕪雜(scruffy)」一詞描述他們這一「反邏輯」的方法,與McCarthy,Kowalski,Feigenbaum,Newell和Simon等人的「簡約(neat)」方案相對。
在1975年的一篇開創性論文中,Minsky注意到與他共事的「蕪雜派」研究者在使用同一類型的工具,即用一個框架囊括所有相關的常識性假設。例如,當我們使用「鳥」這一概念時,腦中會立即浮現出一系列相關事實,如會飛,吃蟲子,等等。我們知道這些假設並不一定正確,使用這些事實的推理也未必符合邏輯,但是這一系列假設組成的結構正是我們所想和所說的一部分。他把這個結構稱為「框架(frames)」。Schank使用了「框架」的一個變種,他稱之為「腳本(scripts)」,基於這一想法他使程序能夠回答關於一篇英語短文的提問。多年之後的物件導向編程採納了AI「框架」研究中的「繼承(inheritance)」概念。
繁榮:1980 - 1987
在80年代,一類名為「專家系統」的AI程序開始為全世界的公司所採納,而「知識處理」成為了主流AI研究的焦點。日本政府在同一年代積極投資AI以促進其第五代計算機工程。80年代早期另一個令人振奮的事件是John Hopfield和David Rumelhart使聯結主義重獲新生。AI再一次獲得了成功。
專家系統獲得賞識
專家系統是一種程序,能夠依據一組從專門知識中推演出的邏輯規則在某一特定領域回答或解決問題。最早的示例由Edward Feigenbaum和他的學生們開發。1965年起設計的Dendral能夠根據分光計讀數分辨混合物。1972年設計的MYCIN能夠診斷血液傳染病。它們展示了這一方法的威力。
專家系統僅限於一個很小的知識領域,從而避免了常識問題;其簡單的設計又使它能夠較為容易地編程實現或修改。總之,實踐證明了這類程序的實用性。直到現在AI才開始變得實用起來。
1980年CMU為DEC(Digital Equipment Corporation,數字設備公司)設計了一個名為XCON的專家系統,這是一個巨大的成功。在1986年之前,它每年為公司省下四千萬美元。全世界的公司都開始研發和應用專家系統,到1985年它們已在AI上投入十億美元以上,大部分用於公司內設的AI部門。為之提供支持的產業應運而生,其中包括Symbolics,Lisp Machines等硬體公司和IntelliCorp,Aion等軟體公司。
知識革命
專家系統的能力來自於它們存儲的專業知識。這是70年代以來AI研究的一個新方向。 Pamela McCorduck在書中寫道,「不情願的AI研究者們開始懷疑,因為它違背了科學研究中對最簡化的追求。智能可能需要建立在對分門別類的大量知識的多種處理方法之上。」 「70年代的教訓是智能行為與知識處理關係非常密切。有時還需要在特定任務領域非常細緻的知識。」知識庫系統和知識工程成為了80年代AI研究的主要方向。
第一個試圖解決常識問題的程序Cyc也在80年代出現,其方法是建立一個容納一個普通人知道的所有常識的巨型資料庫。發起和領導這一項目的Douglas Lenat認為別無捷徑,讓機器理解人類概念的唯一方法是一個一個地教會它們。這一工程幾十年也沒有完成。
重獲撥款:第五代工程
1981年,日本經濟產業省撥款八億五千萬美元支持第五代計算機項目。其目標是造出能夠與人對話,翻譯語言,解釋圖像,並且像人一樣推理的機器。令「蕪雜派」不滿的是,他們選用Prolog作為該項目的主要程式語言。
其他國家紛紛作出響應。英國開始了耗資三億五千萬英鎊的Alvey工程。美國一個企業協會組織了MCC(Microelectronics and Computer Technology Corporation,微電子與計算機技術集團),向AI和信息技術的大規模項目提供資助。 DARPA也行動起來,組織了戰略計算促進會(Strategic Computing Initiative),其1988年向AI的投資是1984年的三倍。
聯結主義的重生
1982年,物理學家John Hopfield證明一種新型的神經網絡(現被稱為「Hopfield網絡」)能夠用一種全新的方式學習和處理信息。大約在同時(早於Paul Werbos),David Rumelhart推廣了反向傳播算法,一種神經網絡訓練方法。這些發現使1970年以來一直遭人遺棄的聯結主義重獲新生。
1986年由Rumelhart和心理學家James McClelland主編的兩卷本論文集「分布式並行處理」問世,這一新領域從此得到了統一和促進。90年代神經網絡獲得了商業上的成功,它們被應用於光字符識別和語音識別軟體。
第二次AI低谷:1987 - 1993
80年代中商業機構對AI的追捧與冷落符合經濟泡沫的經典模式,泡沫的破裂也在政府機構和投資者對AI的觀察之中。儘管遇到各種批評,這一領域仍在不斷前進。來自機器人學這一相關研究領域的Rodney Brooks和Hans Moravec提出了一種全新的人工智慧方案。
人工智慧的低谷
「AI之冬」一詞由經歷過1974年經費削減的研究者們創造出來。他們注意到了對專家系統的狂熱追捧,預計不久後人們將轉向失望。事實被他們不幸言中:從80年代末到90年代初,AI遭遇了一系列財政問題。
變天的最早徵兆是1987年AI硬體市場需求的突然下跌。Apple和IBM生產的台式機性能不斷提升,到1987年時其性能已經超過了Symbolics和其他廠家生產的昂貴的Lisp機。老產品失去了存在的理由:一夜之間這個價值五億美元的產業土崩瓦解。
XCON等最初大獲成功的專家系統維護費用居高不下。它們難以升級,難以使用,脆弱(當輸入異常時會出現莫名其妙的錯誤),成了以前已經暴露的各種各樣的問題(例如資格問題(qualification problem))的犧牲品。專家系統的實用性僅僅局限於某些特定情景。
到了80年代晚期,戰略計算促進會大幅削減對AI的資助。DARPA的新任領導認為AI並非「下一個浪潮」,撥款將傾向於那些看起來更容易出成果的項目。
直到1991年,「第五代工程」並沒有實現,事實上其中一些目標,比如「與人展開交談」,直到2010年也沒有實現。與其他AI項目一樣,期望比真正可能實現的要高得多。
軀體的重要性:Nouvelle AI與嵌入式推理
80年代後期,一些研究者根據機器人學的成就提出了一種全新的人工智慧方案。他們相信,為了獲得真正的智能,機器必須具有軀體 - 它需要感知,移動,生存,與這個世界交互。他們認為這些感知運動技能對於常識推理等高層次技能是至關重要的,而抽象推理不過是人類最不重要,也最無趣的技能。他們號召「自底向上」地創造智能,這一主張復興了從60年代就沉寂下來的控制論。
另一位先驅是在理論神經科學上造詣深厚的David Marr,他於70年代來到MIT指導視覺研究組的工作。他排斥所有符號化方法(不論是McCarthy的邏輯學還是Minsky的框架),認為實現AI需要自底向上地理解視覺的物理機制,而符號處理應在此之後進行。
在發表於1990年的論文「大象不玩象棋(Elephants Don't Play Chess)」中,機器人研究者Rodney Brooks提出了「物理符號系統假設」,認為符號是可有可無的,因為「這個世界就是描述它自己最好的模型。它總是最新的。它總是包括了需要研究的所有細節。訣竅在於正確地,足夠頻繁地感知它。」 在80年代和90年代也有許多認知科學家反對基於符號處理的智能模型,認為身體是推理的必要條件,這一理論被稱為「具身的心靈/理性/ 認知(embodied mind/reason/cognition)」論題。
AI:1993 - 2011
現已年過半百的AI終於實現了它最初的一些目標。它已被成功地用在技術產業中,不過有時是在幕後。這些成就有的歸功於計算機性能的提升,有的則是在高尚的科學責任感驅使下對特定的課題不斷追求而獲得的。不過,至少在商業領域裡AI的聲譽已經不如往昔了。「實現人類水平的智能」這一最初的夢想曾在60年代令全世界的想像力為之著迷,其失敗的原因至今仍眾說紛紜。各種因素的合力將AI拆分為各自為戰的幾個子領域,有時候它們甚至會用新名詞來掩飾「人工智慧」這塊被玷污的金字招牌。AI比以往的任何時候都更加謹慎,卻也更加成功。
里程碑和摩爾定律
1997年5月11日,深藍成為戰勝西洋棋世界冠軍卡斯帕羅夫的第一個計算機系統。2005年,Stanford開發的一台機器人在一條沙漠小徑上成功地自動行駛了131英里,贏得了DARPA挑戰大賽頭獎。2009年,藍腦計畫聲稱已經成功地模擬了部分鼠腦。2011年,IBM 沃森參加《危險邊緣》節目,在最後一集打敗了人類選手。2016年3月,AlphaGo擊敗李世乭,成為第一個不讓子而擊敗職業圍棋棋士的電腦圍棋程式。2017年5月,AlphaGo在中國烏鎮圍棋峰會的三局比賽中擊敗當時世界排名第一的中國棋手柯潔。
這些成就的取得並不是因為範式上的革命。它們仍然是工程技術的複雜應用,但是計算機性能已經今非昔比了。事實上,深藍計算機比克里斯多福·斯特雷奇(Christopher Strachey)在1951年用來下棋的Ferranti Mark 1快一千萬倍。這種劇烈增長可以用摩爾定律描述:計算速度和內存容量每兩年翻一番。計算性能上的基礎性障礙已被逐漸克服。
智能代理
90年代,被稱為「智能代理」的新範式被廣泛接受。儘管早期研究者提出了模塊化的分治策略,但是直到Judea Pearl,Alan Newell等人將一些概念從決策理論和經濟學中引入AI之後現代智能代理範式才逐漸形成。當經濟學中的「理性代理(rational agent)」與計算機科學中的「對象」或「模塊」相結合,「智能代理」範式就完善了。
智能代理是一個系統,它感知周圍環境,然後採取措施使成功的機率最大化。最簡單的智能代理是解決特定問題的程序。已知的最複雜的智能代理是理性的,會思考的人類。智能代理範式將AI研究定義為「對智能代理的學習」。這是對早期一些定義的推廣:它超越了研究人類智能的範疇,涵蓋了對所有種類的智能的研究。
這一範式讓研究者們通過學習孤立的問題找到可證的並且有用的解答。它為AI各領域乃至經濟學,控制論等使用抽象代理概念的領域提供了描述問題和共享解答的一種通用語言。人們希望能找到一種完整的代理架構(像Newell的Soar那樣),允許研究者們應用交互的智能代理建立起通用的智能系統。
「簡約派」的勝利
越來越多的AI研究者們開始開發和使用複雜的數學工具。人們廣泛地認識到,許多AI需要解決的問題已經成為數學,經濟學和運籌學領域的研究課題。數學語言的共享不僅使AI可以與其他學科展開更高層次的合作,而且使研究結果更易於評估和證明。AI已成為一門更嚴格的科學分支。Russell和Norvig(2003)將這些變化視為一場「革命」和「簡約派的勝利」。
Judea Pearl發表於1988年的名著將概率論和決策理論引入AI。現已投入應用的新工具包括貝葉斯網絡,隱馬爾可夫模型,資訊理論,隨機模型和經典優化理論。針對神經網絡和進化算法等「計算智能」範式的精確數學描述也被發展出來。
幕後的AI
AI研究者們開發的算法開始變為較大的系統的一部分。AI曾經解決了大量的難題,這些解決方案在產業界起到了重要作用。應用了AI技術的有數據挖掘,工業機器人,物流,語音識別,銀行業軟體,醫療診斷和Google搜尋引擎等。
AI領域並未從這些成就之中獲得多少益處。AI的許多偉大創新僅被看作計算機科學工具箱中的一件工具。Nick Bostrom解釋說,「很多AI的前沿成就已被應用在一般的程序中,不過通常沒有被稱為AI。這是因為,一旦變得足夠有用和普遍,它就不再被稱為AI了。」
90年代的許多AI研究者故意用其他一些名字稱呼他們的工作,例如信息學,知識系統,認知系統或計算智能。部分原因是他們認為他們的領域與AI存在根本的不同,不過新名字也有利於獲取經費。至少在商業領域,導致AI之冬的那些未能兌現的承諾仍然困擾著AI研究,正如New York Times在2005年的一篇報導所說:「計算機科學家和軟體工程師們避免使用人工智慧一詞,因為怕被認為是在說夢話。」
HAL 9000在哪裡?
1968年亞瑟·克拉克和史丹利·庫柏力克創作的《「2001太空漫遊」》中設想2001年將會出現達到或超過人類智能的機器。他們創造的這一名為HAL-9000的角色是以科學事實為依據的:當時許多頂極AI研究者相信到2001年這樣的機器會出現。
「那麼問題是,為什麼在2001年我們並未擁有HAL呢?」 馬文·閔斯基問道。 Minsky認為,問題的答案是絕大多數研究者醉心於鑽研神經網絡和遺傳算法之類商業應用,而忽略了常識推理等核心問題。另一方面,約翰·麥卡錫則歸咎於資格問題(qualification problem)。雷蒙德·庫茨魏爾相信問題在於計算機性能,根據摩爾定律,他預測具有人類智能水平的機器將在2029年出現。傑夫·霍金認為神經網絡研究忽略了人類大腦皮質的關鍵特性,而簡單的模型只能用於解決簡單的問題。還有許多別的解釋,每一個都對應著一個正在進行的研究計劃。
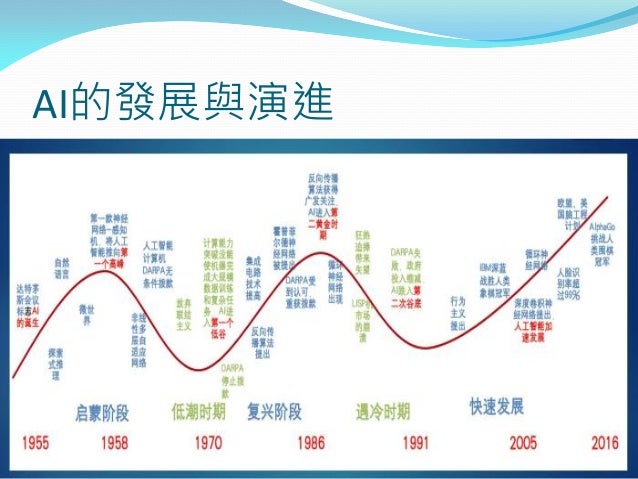
深度學習,大數據和人工智慧:2011至今
進入21世紀,得益於大數據和計算機技術的快速發展,許多先進的機器學習技術成功應用於經濟社會中的許多問題。麥肯錫全球研究院在一份題為《大數據:創新、競爭和生產力的下一個前沿領域》的報告中估計,到2009年,美國經濟所有行業中具有1000名以上員工的公司都至少平均擁有一個200兆兆字節的存儲數據。
到2016年,AI相關產品、硬體、軟體等的市場規模已經超過80億美元,紐約時報評價道AI已經到達了一個熱潮。大數據應用也開始逐漸滲透到其他領域,例如生態學模型訓練、經濟領域中的各種應用、醫學研究中的疾病預測及新藥研發等。深度學習(特別是深度卷積神經網絡和循環網絡)更是極大地推動了圖像和視頻處理、文本分析、語音識別等問題的研究進程。
深度學習
深度學習是機器學習的一個分支,它通過一個有著很多層處理單元的深層網絡對數據中的高級抽象進行建模。根據全局逼近原理(Universal approximation theorem),對於神經網絡而言,如果要擬合任意連續函數,深度性並不是必須的,即使一個單層的網絡,只要擁有足夠多的非線性激活單元,也可以達到擬合目的。但是,目前深度神經網絡得到了更多的關注,這主要是源於其結構層次性,能夠快速建模更加複雜的情況,同時避免淺層網絡可能遭遇的諸多缺點。
然而,深度學習也有自身的缺點。以循環神經網絡為例,一個最常見的問題是梯度消失問題(沿著時間序列反向傳播過程中,梯度逐漸減小到0附近,造成學習停滯)。為了解決這些問題,很多針對性的模型被提出來,例如LSTM(長短期記憶網絡,早在1997年就已經提出,最近隨著RNN的大火,又重新進入大眾視野)、GRU(門控循環神經單元)等等。
現在,最先進的神經網絡結構在某些領域已經能夠達到甚至超過人類平均準確率,例如在計算機視覺領域,特別是一些具體的任務上,比如MNIST數據集(一個手寫數字識別數據集)、交通信號燈識別等。再如遊戲領域,Google的deepmind團隊研發的AlaphaGo,在問題搜索複雜度極高的圍棋上,已經打遍天下無敵手。
文章定位: