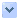鼴鼠公司最近終於生出一顆新的CPU,雖然大部分的人可能都不知道啦。
不過就一個唸資工的人而言,這顆CPU其實還挺有趣的,所以剛好找這個機會來談談這顆產品裡到底用呢哪些課本上教的東西吧!
首先呢,就是超純量(Superscaler),超序執行(out of order),跟Macro- fusion與Micro-fusion。
嗯,唸資工的人都應該知道我在說什麼,對於非本科的人多做一些說明吧:
1. 超純量:
有超純量,就有純量,講的這麼怪的名詞,其實講明了就是RISC啦!
大家都知道x86是經典的CISC CPU架構,不過畢竟受到了速度提升的限制,早在386時期,intel就已經開始導入RISC的架構了,當然,這會讓設計變的複雜,而且會有相容性的問題,因此,發展出所謂的Superscaler這種玩意!簡單的說,一樣是吃x86指令,但是會在內部將其解碼成micro-op,用這種方式將其轉化成RISC的型態(嚴格說起來不盡相同);細節的部分其實可以不用懂,而且該懂的人也原本就懂了,所以就不在著墨,但是若非採用Super scaler架構,後面的超序執行也不用提了。
2.超序執行,Out of order
這裡不是故障的意思,真的就是跳過順序的意思。
舉個例子:
a的值等於10*10*10+1000/512-222+5<<4;
如果(a的內容等於10) 執行A;
否則 執行B;
上面是給非本科的人看的,本科人的話就是:
a= 10*10*10+1000/512-222+5<<4;
if(a==10) goto A;
else goto B;
這個例子很經典,等一下會用到很多次。
(囉唆一下,鼴鼠知道constant的運算compiler會直接算出結果,不過在這裡我們當做會運算)
在這裡假設A的內容就是:
A:
b=((c+d*512)/1024;
而B是:
d=c*c*c+(b+b<<14?b++:b)/512-abs(array[*b+*c[*d]]);
內容隨便啦,總之就是一些囉唆的運算。
首先呢,這裡會用到分歧預測!
什麼意思?
簡單說,當你還不知道a的值為何時,你就不能執行A或B!
聽起來很正常對吧?
不過CPU裡面一次本來就可以 ”同時” 執行很多指令,如果非等到a的結果計算出來才能執行A或B,那整個電路就會”閑”下來,基本上這就是一種浪費!
懂吧?
所謂的分歧預測(branch prediction)!
當然,其中有些trick,各位可以注意到A和B中都沒用到a這個變數,也就是說A與B的執行是與a的內容無關的。
而這種時候,其實A和B可以被同時都執行!也就是說,等a的值被計算出來後,A和B都已經在執行,說不定已經被執行完了,整體的運算速度就會變的更快!
了嗎?也就是說,原本需要兩個單位時間才能執行完,現在只要一個。
這就是out-of-order!當然,實際上不會是這麼單純。
要實現上述的目的,重要的是ALU的數目必須提升,也就是說gate count要增加,耗電量和成本都會提高!
其中最經典的例子就是K8,K8可以同時執行9組ALU運算(理論上來說,最好的情況可以快九倍),但實際上絕大部分的時間,都只有兩組ALU在運作。
因此,這種邏輯的設計其實相當難以取捨,9倍數量的ALU當然跟L2 cache比起來不算什麼,但是在當年而言,這可是要不少錢啊!
雖然以現階段而言,鼴鼠個人覺得intel賣CPU根本就是在賣記憶體(不過這是SRAM)...雖然說他們原本也是做DRAM的啦=_=+

從上面這張圖(Nano的),大家就可以發現1MB的L2 cache幾乎占了超過1/3的gate count,也就是說,你如果買了這顆CPU,有超過1/3的錢其實在買快取。
這張圖是網路上偷來的intel core 2 duo的6600的圖,左邊黑黑的就是L2cache,右邊是ALU,可以看到上下是對襯一樣的東西。
這個快取的數量也不是開玩笑的。
最後的Macro-fusion也挺容易理解的,簡單說就是把兩個指令合成一個!
例如上面不是用了:
if(a==10) goto A嗎?
a==10是一個比較指令,
goto A是一個跳躍指令。
簡單說就是把這兩個指令合成一個!就叫做Macro-fusion,例如:
cmp_je a,10,A
cmp_je,就當作是compare and jump if equal即可。
如此,原本需要兩個單位時間來執行的指令,就變成只需要一個單位時間。
(注:原本應為兩條指令 cmp a,10 and je A)
而micro-fusion也是類似,不過就是用於micro-op中,也就是大家熟知的IF,DE,EXE,WB,MEM這些玩意上。
當然,真的要講的詳細的話,是需要一整本課本的,大家就當作是聊天用的素材吧。
nano的話,從White paper看來,未來會推出超過1MB L2快取的版本,由於支援1033MHZ的FSB,因此也不排除未來會推出更高時脈的版本;雙核心的話,就要等明年了,不過由於nano本來就支援MP,所以應該可以順利推出才對,除非L2 cache的設計要跟AMD一樣,那就得拖很久了。
提外話,GPU中SIMD的事情更為囉唆,不過這是後話了。
文章定位:
人氣(449) | 回應(0)| 推薦 (
0)| 收藏 (
0)|
轉寄
全站分類:
不分類